Predicting Device Failure
- 28 mins#import libraries
import pandas as pd
import numpy as np
from scipy.stats.mstats import mode
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import cross_val_score
from sklearn import linear_model
from sklearn.cross_validation import train_test_split, KFold
from sklearn.metrics import confusion_matrix, accuracy_score
import matplotlib.pyplot as plt
import seaborn as sns; sns.set()
from IPython.display import Image, display
%matplotlib inline
Introduction
This is a Project-based Learning (PBL) from the DevMasters - Mastering Applied Data Science program. We were given a dataset that has 12 columns and no description of each, except the dates, device ID and a target variable, failure, which is binary. Per our instructor, it is a common practice for employers to use such datasets to test prospective candidates. The candidate is to build a predictive model within a short time and demonstrate his/her ability of solving the problem.
Business Objective
The business objective is to predict failure of the device based on a year’s worth of data.
The dataset
This dataset is relatively clean. There is no need for data cleaning. Nor is feature engineering required. Each record in the dataset is a trip to the device when it requires maintenance. There are no missing values. What is unique about the dataset is that the failure (the minority) class is heavily under represented to that of the majority class.
Below I go through some exploratory data analysis, and get to modeling stage rather quickly to discuss the issues of imbalanced machine learning, using both oversampling and undersampling approaches. I use the Index of Balanced Accuracy (IBA) and geometric mean of specificity and sensitivity to compare the performance of a RandomfForest classifier between the two approaches. A Linear Support Vector classifier was also run.
Exploratory Data Analysis
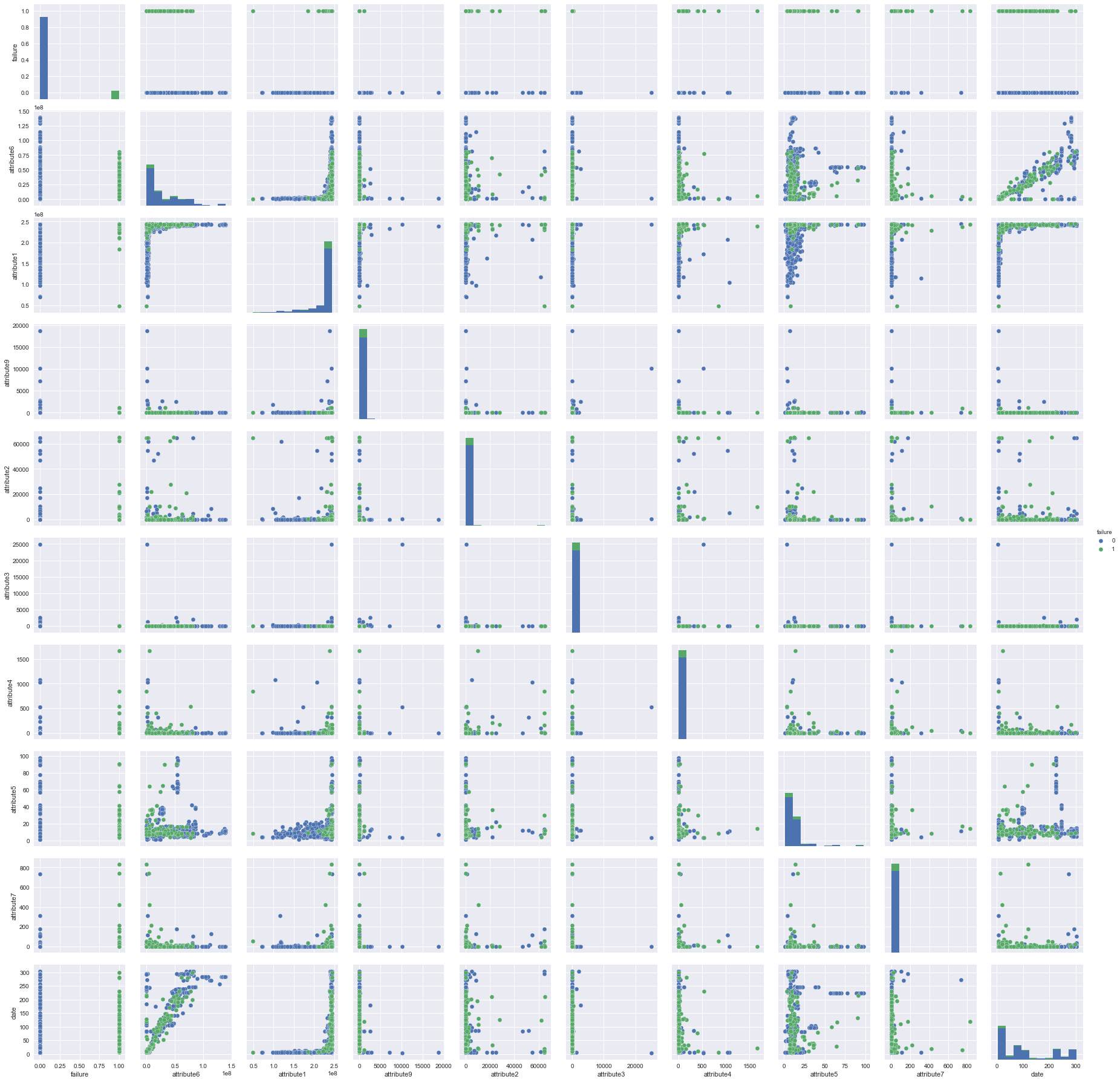
An exploratory data analysis reveals that
- All attributes are of integer data type;
- Attribute7 and attribute8 are exactly the same. Attribute8 is dropped;
- Of the 124,494 records for the year, there were only 106 failures. The date is when a device is visited. Either groupby function or pivot table function can be used to aggregate to the device level;
- Some attributes have limited number of distictive values, indicating that they are likely to be categorical variable, such as attribute4, 7 and 9;
- Attribute1 and 6 are likely to be continuous variables;
- Attribute3 and 9 are dropped based on the correlation with the failure variable;
- numpy log(1 + attribute) is used to transform some attributes;
After groupby function is applied, there were 1,062 majority cases and 106 minority cases (roughly 10%). And it is the starting point of this demonstration to show that in imbalanced machine learning oversampling and undersampling approaches are frequently used to deal with imbalanced datasets. And it turns out that undersampling approach can do better than oversampling approach, even when the dataset is relatively small.
#read in the dataset
df = pd.read_csv('failures.csv')
#check if there are missing values
df.isnull().sum()
date 0
device 0
failure 0
attribute1 0
attribute2 0
attribute3 0
attribute4 0
attribute5 0
attribute6 0
attribute7 0
attribute8 0
attribute9 0
dtype: int64
Groupby (will lose an object column) and merge # of dates file
#dimension of the dataframe before aggregation
df.shape
(124494, 12)
df['failure'].value_counts(dropna=False)
0 124388
1 106
Name: failure, dtype: int64
#aggregate by device, the number of dates a certain device is visited for maintenance
date_cnt = df.groupby('device')['date'].count()
#groupby device numerical variables - either use max or sum
df = df.groupby('device').agg({'failure' : 'sum', 'attribute6' : 'sum',
'attribute1':'max', 'attribute9': 'max',
'attribute2':'max', 'attribute3': 'max', 'attribute4' : 'max',
'attribute5':'max', 'attribute7': 'max'})
#a total of 1168 unique devices
df.shape
(1168, 9)
#merge the dataframe with aggregated the number of time a device is visited
result = pd.concat([df, date_cnt], axis=1, ignore_index=False)
result.shape
(1168, 10)
#review last 30 observations of the analytic dataset
result.tail(30)
| failure | attribute6 | attribute1 | attribute9 | attribute2 | attribute3 | attribute4 | attribute5 | attribute7 | date | |
|---|---|---|---|---|---|---|---|---|---|---|
| device | ||||||||||
| Z1F1A0LM | 0 | 80321583 | 243675552 | 0 | 0 | 0 | 0 | 7 | 0 | 295 |
| Z1F1A0RP | 0 | 62743931 | 243835032 | 0 | 0 | 0 | 0 | 7 | 0 | 295 |
| Z1F1A1HH | 0 | 72347021 | 243813992 | 0 | 0 | 0 | 0 | 7 | 0 | 295 |
| Z1F1A7MG | 0 | 569544 | 199176360 | 0 | 168 | 0 | 11 | 7 | 0 | 6 |
| Z1F1A83K | 0 | 3076 | 240870336 | 0 | 0 | 0 | 0 | 12 | 0 | 112 |
| Z1F1AD0M | 0 | 19485542 | 241675272 | 0 | 0 | 0 | 1 | 21 | 0 | 82 |
| Z1F1AF54 | 0 | 114 | 241932032 | 0 | 0 | 0 | 0 | 7 | 0 | 6 |
| Z1F1AFF2 | 0 | 3088 | 243992616 | 0 | 112 | 0 | 0 | 12 | 0 | 84 |
| Z1F1AFT5 | 0 | 120 | 115439712 | 0 | 0 | 0 | 0 | 7 | 0 | 6 |
| Z1F1AG5N | 1 | 186 | 222479304 | 0 | 32 | 0 | 10 | 7 | 0 | 9 |
| Z1F1AGLA | 0 | 1203873 | 134404400 | 0 | 0 | 0 | 0 | 8 | 0 | 5 |
| Z1F1AGN5 | 0 | 1368263 | 234101200 | 0 | 0 | 0 | 0 | 8 | 0 | 5 |
| Z1F1AGW1 | 0 | 1412352 | 238702720 | 18701 | 0 | 0 | 0 | 7 | 0 | 5 |
| Z1F1B6H4 | 0 | 108 | 224579736 | 1 | 0 | 0 | 0 | 7 | 0 | 6 |
| Z1F1B6NP | 0 | 9481 | 242994104 | 1 | 0 | 0 | 0 | 12 | 0 | 292 |
| Z1F1B799 | 0 | 11879 | 243098976 | 0 | 0 | 0 | 0 | 16 | 0 | 245 |
| Z1F1CZ35 | 0 | 25727658 | 243936472 | 3 | 0 | 0 | 0 | 9 | 0 | 103 |
| Z1F1FCH5 | 1 | 4312955 | 241866296 | 0 | 0 | 0 | 6 | 7 | 24 | 19 |
| Z1F1FZ9J | 0 | 10779606 | 242058976 | 0 | 0 | 0 | 0 | 5 | 0 | 48 |
| Z1F1HEQR | 0 | 992451 | 120474016 | 0 | 0 | 0 | 0 | 4 | 0 | 6 |
| Z1F1HSWK | 0 | 2161548 | 208877824 | 6 | 0 | 0 | 0 | 5 | 0 | 6 |
| Z1F1Q9BD | 0 | 19891562 | 243823328 | 0 | 0 | 0 | 0 | 7 | 0 | 82 |
| Z1F1R76A | 0 | 84906596 | 243842072 | 12 | 0 | 0 | 0 | 8 | 0 | 245 |
| Z1F1RE71 | 0 | 1107448 | 241454264 | 0 | 0 | 1 | 0 | 3 | 0 | 6 |
| Z1F1RJFA | 1 | 41342401 | 243890056 | 0 | 62296 | 1 | 9 | 4 | 0 | 124 |
| Z1F1VMZB | 0 | 65039417 | 242361392 | 0 | 0 | 0 | 0 | 5 | 0 | 292 |
| Z1F1VQFY | 1 | 31179620 | 243071840 | 0 | 0 | 0 | 0 | 7 | 0 | 125 |
| Z1F26YZB | 0 | 24265015 | 241938368 | 0 | 0 | 1 | 0 | 1 | 0 | 84 |
| Z1F282ZV | 0 | 15868420 | 243169296 | 0 | 0 | 1 | 0 | 1 | 0 | 84 |
| Z1F2PBHX | 0 | 13186666 | 243935864 | 0 | 0 | 0 | 0 | 5 | 0 | 83 |
#minority class has 106 observations, whereas the majority has 1,062 observations
result['failure'].value_counts(dropna=False)
0 1062
1 106
Name: failure, dtype: int64
#Examine the correlation among the variables
result.corr()
| failure | attribute6 | attribute1 | attribute9 | attribute2 | attribute3 | attribute4 | attribute5 | attribute7 | date | |
|---|---|---|---|---|---|---|---|---|---|---|
| failure | 1.000000 | -0.027355 | 0.099725 | -0.012201 | 0.178851 | -0.011711 | 0.181233 | 0.077348 | 0.204515 | -0.017000 |
| attribute6 | -0.027355 | 1.000000 | 0.411288 | -0.046693 | -0.022909 | -0.018768 | -0.057795 | 0.150072 | -0.050576 | 0.879975 |
| attribute1 | 0.099725 | 0.411288 | 1.000000 | 0.008648 | -0.071950 | 0.016221 | -0.113202 | 0.162886 | -0.007493 | 0.474314 |
| attribute9 | -0.012201 | -0.046693 | 0.008648 | 1.000000 | -0.006273 | 0.447703 | 0.078266 | -0.028133 | 0.015573 | -0.056289 |
| attribute2 | 0.178851 | -0.022909 | -0.071950 | -0.006273 | 1.000000 | -0.003510 | 0.347504 | -0.006053 | 0.081082 | -0.017311 |
| attribute3 | -0.011711 | -0.018768 | 0.016221 | 0.447703 | -0.003510 | 1.000000 | 0.189068 | -0.023523 | -0.004162 | -0.022751 |
| attribute4 | 0.181233 | -0.057795 | -0.113202 | 0.078266 | 0.347504 | 0.189068 | 1.000000 | -0.006778 | 0.060772 | -0.070330 |
| attribute5 | 0.077348 | 0.150072 | 0.162886 | -0.028133 | -0.006053 | -0.023523 | -0.006778 | 1.000000 | 0.000141 | 0.182373 |
| attribute7 | 0.204515 | -0.050576 | -0.007493 | 0.015573 | 0.081082 | -0.004162 | 0.060772 | 0.000141 | 1.000000 | 0.000559 |
| date | -0.017000 | 0.879975 | 0.474314 | -0.056289 | -0.017311 | -0.022751 | -0.070330 | 0.182373 | 0.000559 | 1.000000 |
#visualization of correlations using seaborn pairplot
sns.pairplot(result, hue='failure') #due to display issue of Indigo theme. the image is display manually
<seaborn.axisgrid.PairGrid at 0x1a26ddbe10>
Logistic regression consideration
Since this is a classification problem, my initial naive approach is to try a logistic regression to see if it works without worrying about imbalanced dataset. Selected attributes were tried to see if some attribute would display an “S” curve when plotting against the target variable. I only used attribute4 for the demonstration.
In a separate notebook I tried a logistic regression to predict the failure using those attributes that display “S” shape. The results are not good and are not shown here. You can give a try to see for yourself. When dealing with imbalanced dataset you really have to address the imbalance of your dataset and use imbalanced learn package.
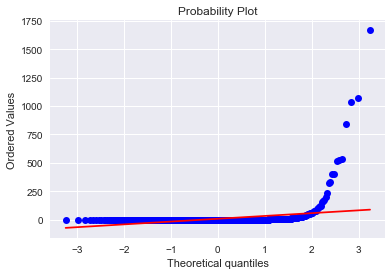
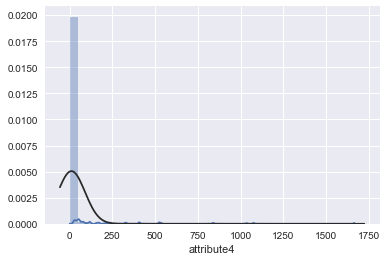
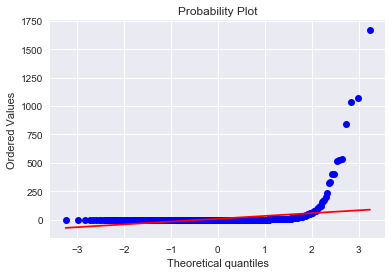
#visualization using Seaborn; distribution plot; probability plot against normal distribution
from scipy import stats
from scipy.stats import norm
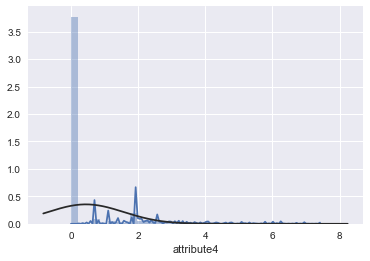
sns.distplot(result['attribute4'],fit=norm)
fig = plt.figure()
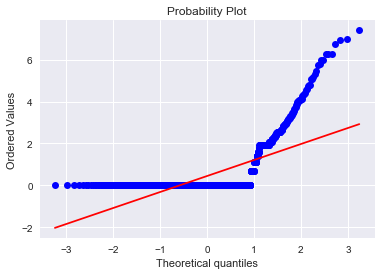
res=stats.probplot(result['attribute4'], plot=plt)
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "

ax = sns.regplot(x="attribute4", y="failure", data=result, logistic=True, n_boot=500, y_jitter=.03)
/Users/leicao/anaconda3/lib/python3.6/site-packages/statsmodels/genmod/families/family.py:880: RuntimeWarning: invalid value encountered in true_divide
n_endog_mu = self._clean((1. - endog) / (1. - mu))

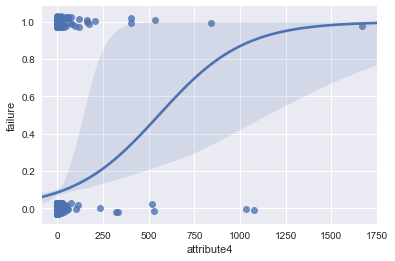
The “S”-shape displayed here indicates that attribute4 is a good candidate to classify failure of a device. I also tried a log(1 + attribute4) transformation to see if it is normal-like
#log(1+attribute4) transformation
result['attribute4'] = np.log1p(result['attribute4'])
ax = sns.regplot(x="attribute4", y="failure", data=result, logistic=True, n_boot=500, y_jitter=.03)
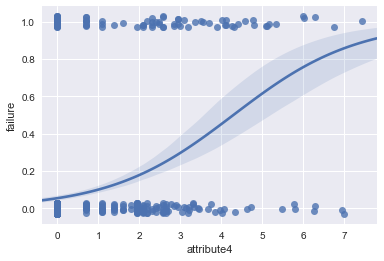
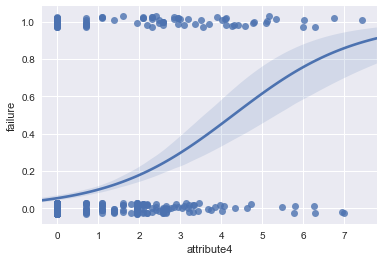
#distribution plot on the transformed attribute4
sns.distplot(result['attribute4'],fit=norm)
fig = plt.figure()
res=stats.probplot(result['attribute4'], plot=plt)
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
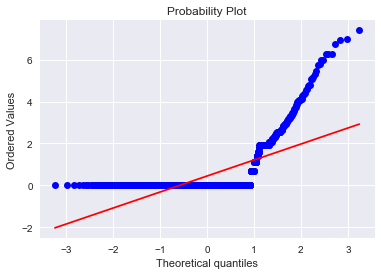

One can repeat the exercise for Attibute7
These two codes can be used to assess if an attribute is categorical or continuous variable
result[‘attribute1’].value_counts(dropna=False) sns.barplot(result[‘attribute1’])
#numpy log(1 + x) transformation is used
result['attribute1'] = np.log1p(result['attribute1'])
result['attribute2'] = np.log1p(result['attribute2'])
result['attribute6'] = np.log1p(result['attribute6'])
result['attribute7'] = np.log1p(result['attribute7'])
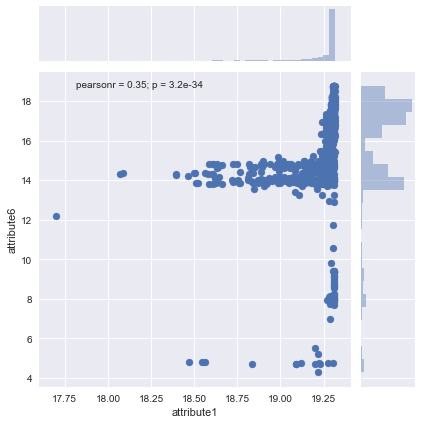
#attribute1 and attribute6 are two continuous variables; to see a scatterplot of them
sns.jointplot('attribute1', 'attribute6', data=result)
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
<seaborn.axisgrid.JointGrid at 0x1a2c189a90>

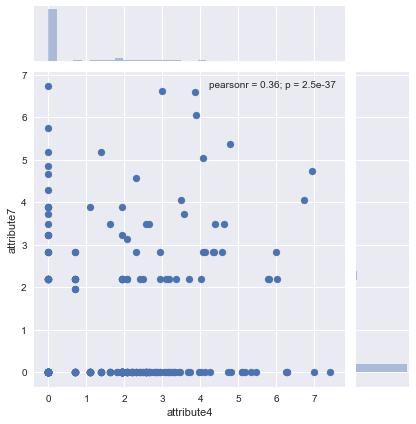
#scatterplot of attribute4 and attribute7
sns.jointplot('attribute4', 'attribute7', data=result)
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
/Users/leicao/anaconda3/lib/python3.6/site-packages/matplotlib/axes/_axes.py:6462: UserWarning: The 'normed' kwarg is deprecated, and has been replaced by the 'density' kwarg.
warnings.warn("The 'normed' kwarg is deprecated, and has been "
<seaborn.axisgrid.JointGrid at 0x1a2c189550>

Modeling
Oversampling
Synthetic Minority oversampling technique SMOTE and a Linear Support Vector Classifier (LinearSVC)
#only attribute1, attribute2, attribute4, attribute5, attribute6, and attribute7 are used in the model
X = result.drop(['failure','attribute3','attribute9'], axis=1)
y = result['failure']
X_train, X_test, y_train, y_test = train_test_split( X, y, train_size=0.8, random_state=42, stratify=df[‘failure’]) # make sure it is representative
X_train.shape, y_train.shape, X_test.shape, y_test.shape
from sklearn.svm import LinearSVC
from imblearn import over_sampling as os
from imblearn import pipeline as pl
from imblearn.metrics import geometric_mean_score, make_index_balanced_accuracy, classification_report_imbalanced
print(__doc__)
RANDOM_STATE = 42
Automatically created module for IPython interactive environment
pipeline = pl.make_pipeline(os.SMOTE(random_state=RANDOM_STATE), LinearSVC(random_state=RANDOM_STATE))
# Split the data. May not need to specify 80/20 for training set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=0.8, random_state=RANDOM_STATE, stratify=df['failure'])
# Train the classifier with balancing
pipeline.fit(X_train, y_train)
# Test the classifier and get the prediction
y_pred_bal = pipeline.predict(X_test)
pipeline
Pipeline(memory=None,
steps=[('smote', SMOTE(k=None, k_neighbors=5, kind='regular', m=None, m_neighbors=10, n_jobs=1,
out_step=0.5, random_state=42, ratio='auto', svm_estimator=None)), ('linearsvc', LinearSVC(C=1.0, class_weight=None, dual=True, fit_intercept=True,
intercept_scaling=1, loss='squared_hinge', max_iter=1000,
multi_class='ovr', penalty='l2', random_state=42, tol=0.0001,
verbose=0))])
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((934, 7), (234, 7), (934,), (234,))
#in the training dataset majority is 849 and minority class or the target is 85
y_train.value_counts()
0 849
1 85
Name: failure, dtype: int64
y_test.value_counts()
0 213
1 21
Name: failure, dtype: int64
The geometric mean corresponds to the square root of the product of the sensitivity and specificity. Combining the two metrics should account for the balancing of the dataset.
This refers to the paper: “Index of Balanced Accuracy: A Performance Measure for Skewed Class Distributions, by V. Garcia, et al.
A new simple index called Dominance is proposed for evaluating the relationship between the TPrate and TNrate, which is defined as Dominance = TPrate - TNrate. And -1 <= Dominance <= +1
the Dominance is to inform which is the dominant class and how significance is its dominance relationship. In practice, the Dominance can be interpreted as an indicator of how balanced the TPrate and the TNrate are
alpha here is a weighting factor on the value of Dominance. 0 <= alpha <= 1. Significant effects are obtained for alpha <= 0.5 and the default is 0.1.
#print the geometric mean of this LinearSVC using SMOTE
print('The geometric mean is {}'.format(geometric_mean_score(y_test,y_pred_bal)))
The geometric mean is 0.7566679519100818
#alpha = 0.1 and 0.5 give the same IBA result here
alpha = 0.1
geo_mean = make_index_balanced_accuracy(alpha=alpha, squared=True)(geometric_mean_score)
print('The IBA using alpha = {} and the geometric mean: {}'.format(
alpha, geo_mean(y_test, y_pred_bal)))
alpha = 0.5
geo_mean = make_index_balanced_accuracy(alpha=alpha, squared=True)(geometric_mean_score)
print('The IBA using alpha = {} and the geometric mean: {}'.format(alpha, geo_mean(y_test, y_pred_bal)))
The IBA using alpha = 0.1 and the geometric mean: 0.5725463894477979
The IBA using alpha = 0.5 and the geometric mean: 0.5725463894477979
test_cm = confusion_matrix(y_test, y_pred_bal)
test_cm
array([[197, 16],
[ 8, 13]])
accuracy_score(y_test, y_pred_bal)
0.8974358974358975
Note
The accuracy score of 0.897 is the sum of diagonals of the confusion matric divided by the total test sample size of 234. While the accuracy score seems high, however, we should take interest only in the second row. In another word, this LinearSVC only predicts 13 failures out of 21, or 61.9% only.
#summary statistics for model comparison Linear Support Vector Classifier, oversampling
print(classification_report_imbalanced(y_test, y_pred_bal))
pre rec spe f1 geo iba sup
0 0.96 0.92 0.62 0.94 0.76 0.59 213
1 0.45 0.62 0.92 0.52 0.76 0.56 21
avg / total 0.91 0.90 0.65 0.90 0.76 0.59 234
Note that
- pre is precision, which is a measure of result relevancy;
- rec is recall, which is the same as sensitivity. Recall is a measure of how many truly relevant results are returned;
- spe is specificity;
- f1 is the harmonic average of the precision and recall;
- geo is the geometric mean of specificity and sensitivity;
- iba is the index of imbalanced accuracy;
Again we should pay attention to the second row of 1.
SMOTE approach with a RandomForest Classifier; both oversample and undersample apply on the training dataset only
from collections import Counter
from imblearn.over_sampling import SMOTE, ADASYN
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_sample(X_train, y_train)
print('Resampled dataset shape {}'.format(Counter(y_res)))
print(sorted(Counter(y_res).items()))
Resampled dataset shape Counter({0: 849, 1: 849})
[(0, 849), (1, 849)]
Note that the sample sizes are 849 for both majority and monority classess for oversampling
A RandomForest Classifier
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_estimators=5000, random_state=21)
a = rf.fit(X_res, y_res)
rf.score(X_res, y_res)
1.0
rf_res_pred=rf.predict(X_res)
rf_cm = confusion_matrix(y_res, rf_res_pred)
rf_cm
array([[849, 0],
[ 0, 849]])
Note that this RandomForest classifier predicts perfectly on the training dataset
#note that I am using accuracy as the scoring methodolgy here. There are other options
rf_cv_score = cross_val_score(a, X_res, y_res, cv=10, scoring='accuracy')
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-92-6331789fd88c> in <module>()
1 #note that I am using accuracy as the scoring methodolgy here. There are other options
----> 2 rf_cv_score = cross_val_score(a, X_res, y_res, cv=10, scoring='accuracy')
~/anaconda3/lib/python3.6/site-packages/sklearn/model_selection/_validation.py in cross_val_score(estimator, X, y, groups, scoring, cv, n_jobs, verbose, fit_params, pre_dispatch)
340 n_jobs=n_jobs, verbose=verbose,
341 fit_params=fit_params,
--> 342 pre_dispatch=pre_dispatch)
343 return cv_results['test_score']
344
~/anaconda3/lib/python3.6/site-packages/sklearn/model_selection/_validation.py in cross_validate(estimator, X, y, groups, scoring, cv, n_jobs, verbose, fit_params, pre_dispatch, return_train_score)
204 fit_params, return_train_score=return_train_score,
205 return_times=True)
--> 206 for train, test in cv.split(X, y, groups))
207
208 if return_train_score:
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/parallel.py in __call__(self, iterable)
777 # was dispatched. In particular this covers the edge
778 # case of Parallel used with an exhausted iterator.
--> 779 while self.dispatch_one_batch(iterator):
780 self._iterating = True
781 else:
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/parallel.py in dispatch_one_batch(self, iterator)
623 return False
624 else:
--> 625 self._dispatch(tasks)
626 return True
627
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/parallel.py in _dispatch(self, batch)
586 dispatch_timestamp = time.time()
587 cb = BatchCompletionCallBack(dispatch_timestamp, len(batch), self)
--> 588 job = self._backend.apply_async(batch, callback=cb)
589 self._jobs.append(job)
590
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/_parallel_backends.py in apply_async(self, func, callback)
109 def apply_async(self, func, callback=None):
110 """Schedule a func to be run"""
--> 111 result = ImmediateResult(func)
112 if callback:
113 callback(result)
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/_parallel_backends.py in __init__(self, batch)
330 # Don't delay the application, to avoid keeping the input
331 # arguments in memory
--> 332 self.results = batch()
333
334 def get(self):
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/parallel.py in __call__(self)
129
130 def __call__(self):
--> 131 return [func(*args, **kwargs) for func, args, kwargs in self.items]
132
133 def __len__(self):
~/anaconda3/lib/python3.6/site-packages/sklearn/externals/joblib/parallel.py in <listcomp>(.0)
129
130 def __call__(self):
--> 131 return [func(*args, **kwargs) for func, args, kwargs in self.items]
132
133 def __len__(self):
~/anaconda3/lib/python3.6/site-packages/sklearn/model_selection/_validation.py in _fit_and_score(estimator, X, y, scorer, train, test, verbose, parameters, fit_params, return_train_score, return_parameters, return_n_test_samples, return_times, error_score)
456 estimator.fit(X_train, **fit_params)
457 else:
--> 458 estimator.fit(X_train, y_train, **fit_params)
459
460 except Exception as e:
~/anaconda3/lib/python3.6/site-packages/sklearn/ensemble/forest.py in fit(self, X, y, sample_weight)
314 for i in range(n_more_estimators):
315 tree = self._make_estimator(append=False,
--> 316 random_state=random_state)
317 trees.append(tree)
318
~/anaconda3/lib/python3.6/site-packages/sklearn/ensemble/base.py in _make_estimator(self, append, random_state)
128
129 if random_state is not None:
--> 130 _set_random_states(estimator, random_state)
131
132 if append:
~/anaconda3/lib/python3.6/site-packages/sklearn/ensemble/base.py in _set_random_states(estimator, random_state)
50 random_state = check_random_state(random_state)
51 to_set = {}
---> 52 for key in sorted(estimator.get_params(deep=True)):
53 if key == 'random_state' or key.endswith('__random_state'):
54 to_set[key] = random_state.randint(MAX_RAND_SEED)
~/anaconda3/lib/python3.6/site-packages/sklearn/base.py in get_params(self, deep)
231 # This is set in utils/__init__.py but it gets overwritten
232 # when running under python3 somehow.
--> 233 warnings.simplefilter("always", DeprecationWarning)
234 try:
235 with warnings.catch_warnings(record=True) as w:
~/anaconda3/lib/python3.6/warnings.py in simplefilter(action, category, lineno, append)
155 assert isinstance(lineno, int) and lineno >= 0, \
156 "lineno must be an int >= 0"
--> 157 _add_filter(action, None, category, None, lineno, append=append)
158
159 def _add_filter(*item, append):
~/anaconda3/lib/python3.6/warnings.py in _add_filter(append, *item)
157 _add_filter(action, None, category, None, lineno, append=append)
158
--> 159 def _add_filter(*item, append):
160 # Remove possible duplicate filters, so new one will be placed
161 # in correct place. If append=True and duplicate exists, do nothing.
KeyboardInterrupt:
rf_cv_score
rf_cv_score.mean()
accuracy_score(y_res, rf_res_pred)
rf_test_pred=rf.predict(X_test)
rf_test_cm = confusion_matrix(y_test, rf_test_pred)
rf_test_cm
accuracy_score(y_test, rf_test_pred)
Note
The accuracy score of this classifier is high: 224 out of 234, or 95.7%; however, this classifier only predicts 14 failures out of 21, or 66.7% on the test data
from imblearn.metrics import classification_report_imbalanced
print(classification_report_imbalanced(y_test,rf_test_pred))
Note
When comapred to In[38], the RandomForest classifier has higher IBA (0.64 vs 0.56) and geometric mean (0.81 vs 0.76) than those of LinearSVC classifier using oversampling approach
Adaptive Synthetic oversampling approach and a LinearSVC
X_resampled, y_resampled = ADASYN().fit_sample(X_train, y_train)
print(sorted(Counter(y_resampled).items()))
clf_adasyn = LinearSVC().fit(X_resampled, y_resampled)
clf_adasyn.score(X_resampled, y_resampled)
lsvc_res_pred=clf_adasyn.predict(X_resampled)
lsvc_cm = confusion_matrix(y_resampled, lsvc_res_pred)
lsvc_cm
lsvc_cv_score = cross_val_score(clf_adasyn, X_resampled, y_resampled, cv=10, scoring='accuracy')
lsvc_cv_score
lsvc_cv_score.mean()
accuracy_score(y_resampled, lsvc_res_pred)
lsvc_test_pred=clf_adasyn.predict(X_test)
lsvc_test_cm = confusion_matrix(y_test, lsvc_test_pred)
lsvc_test_cm
Note
This LinearSVC classifier with ADASYN oversampling approach perform badly with test data - only predicts 12 out 21 failures or 57.1%
print(classification_report_imbalanced(y_test,lsvc_test_pred))
accuracy_score(y_test, lsvc_test_pred)
Note
The results are similar to that in [38]
Undersampling
Undersampling approach and a RandomForest Classifier
from imblearn.under_sampling import RandomUnderSampler
rus = RandomUnderSampler(random_state=42)
X_und, y_und = rus.fit_sample(X_train, y_train)
print('Resampled dataset shape {}'.format(Counter(y_und)))
Note that the sample sizes are 85 for both majority and minority classess - undersampling
und_rf = RandomForestClassifier(n_estimators=5000, random_state=21)
u = und_rf.fit(X_und, y_und)
und_rf.score(X_und, y_und)
und_rf_pred=und_rf.predict(X_und)
und_rf_cm = confusion_matrix(y_und, und_rf_pred)
und_rf_cm
Note
This RandomForest classifier predicts perfectly on the training dataset
und_rf_cv_score = cross_val_score(u, X_und, y_und, cv=10, scoring='accuracy')
und_rf_cv_score
und_rf_cv_score.mean()
accuracy_score(y_und, und_rf_pred)
und_rf_test_pred=und_rf.predict(X_test)
und_rf_test_cm = confusion_matrix(y_test, und_rf_test_pred)
und_rf_test_cm
accuracy_score(y_test, und_rf_test_pred)
Undersampling & a RandomForest Classifier
print(classification_report_imbalanced(y_test,und_rf_test_pred))
Oversampling & a RandomForest Classifier
print(classification_report_imbalanced(y_test,rf_test_pred))
Conclusion
We need to pay attention to the rows labeled ‘1’ as we are more interested in the approach that yields better prediction of 1’s. Using the same RandomForest classifier, the undersampling approach has a higher IBA statistic compared to that of oversampling (0.71 vs. 0.64).
Another measure of comparison is the geometric mean statistic. The geometric mean corresponds to the square root of the product of the sensitivity and specificity. Combining the two metrics should account for the balancing of the dataset. Again, the undersampling approach has a higher geometric mean than that of the oversampling (0.85 vs. 0.81).
In an imbalanced classification problem, it is important to balance the training set in order to obtain a decent classifier. In addition, appropriate metrics need to be used, such as the Index of Balanced Accuracy (IBA) and geometric mean of specificity and sensitivity.

Albert F. Lee, Ph.D.
A Man who loves classical music, especially Schubert's and Dvorak's music